聊聊Elasticsearch中的文本分析
本文使用到的是Elasticsearch-7.5.2与Lucene-8.3.0
Elasticsearch中的string类型存在着两种不同的类型。一种是结构化的数据称为keyword,elasticsearch在索引时不会对这类数据做任何的处理;另一种是非结构化的数据称为text,elasticsearch在对这类型的数据做索引之前,会先对原始的string数据做一定的分析处理,之后得到一些结构化的数据结果,然后针对这些结构化的数据做进一步的处理。
例如一个field的类型是text,则Elasticsearch在对这个字段进行索引的时候,会先把这个field的值分词为tokens之后再保存这些tokens。而在查询时如果我们使用match查询,则Elasticsearch会对match查询的值进行分词得到tokens,之后才会使用这些tokens进行真正的查询操作。
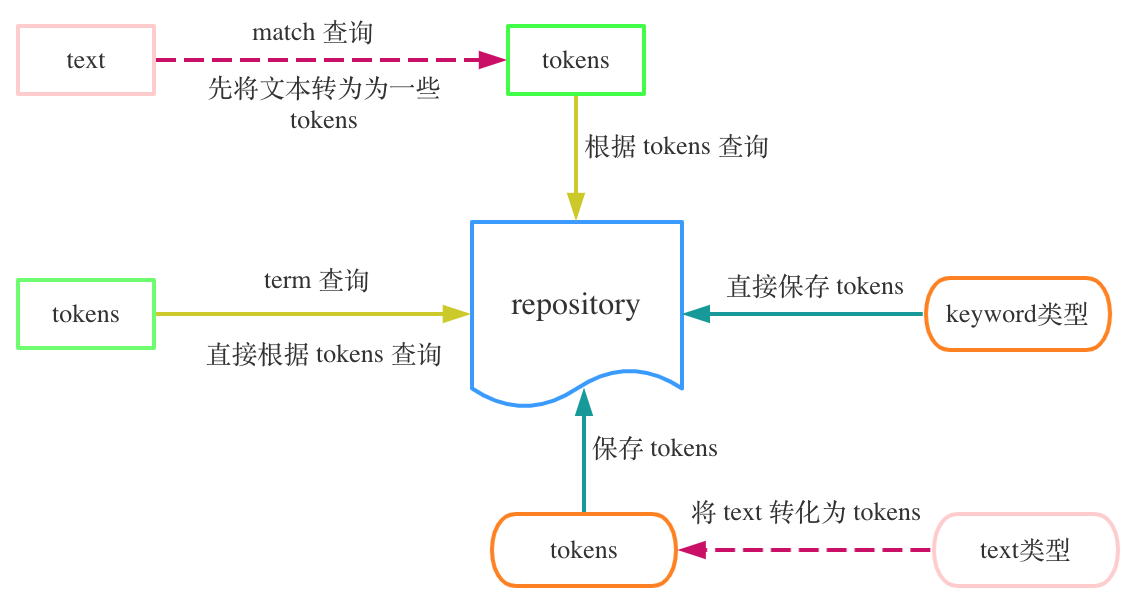
上图显示了Elasticsearch中结构化数据与非结构化数据的保存与查询流程,需要注意的是,Elasticsearch最终只保存结构化的数据,不会保存非结构化的数据。因此我们可以保存一个text类型的数据到ES中,之后使用term方式来进行查询,这也是可以的。
Elasticsearch Text Analysis
从非结构化字符串转化为结构化字符串的过程在Elasticsearch中称为Text analysis,Text analysis流程又分为如下的几个子流程:
- 使用零个或者多个Character filters,对原始的文本进行一些处理
- 使用唯一的Tokenizer,对原始的文本进行分词处理,得到一些tokens/terms
- 使用零个或者多个Token filters,对上一步的tokens继续进行处理,例如合并同义词等
我们可以使用如下命令在es中给一个text字段设置指定的analyzer
PUT my_index
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "whitespace",
"search_analyzer": "simple" # 可选,默认是analyzer的值
}
}
}
}
以上的analyzer为字段在索引时使用,在查询时字段按照如下优先级使用analyzer进行分析:
- 查询时手动指定的analyzer
- 被查询字段的search_analyzer属性
- 索引的default的analyzer的type
- 被查询字段的analyzer属性
es中包含了很多内置的analyzer,例如上面的simple和whitespace,这些analyzer能够做到开箱即用。此外es中还包含了很多内置的filter、tokenizer和char_filter,我们也可以使用这些基础组件构建出一些自定义的analyzer,如下就是一个例子
PUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom", # 这里设置为custom表示自定义一个analyzer
"tokenizer": "standard",
"char_filter": [
"html_strip"
],
"filter": [
"lowercase",
"asciifolding"
]
}
}
}
}
}
es的自定义analyzer功能给文本处理提供了极大的方便,在内置的analyzer无法满足我们的文本分析需求时,我们可以使用内置的character_filter、tokenizer和token_filter来构建符合我们需要的自定义analyzer,这已经十分强大了。但是在有的时候,即使是由character_filter、tokenizer和token_filter自定义的analyzer也无法满足我们的文本分析要求,这时候就需要用到elasticsearch的Analysis插件体系了。
Elasticsearch Plugins
Elasticsearch包含了很多官方以及社区贡献的plugin,这些插件都可以在es中进行安装或删除:
./bin/elasticsearch-plugin install analysis-smartcn
./bin/elasticsearch-plugin remove analysis-smartcn
# 或者下载了安装包之后手动的安装plugin
./bin/elasticsearch-plugin install file:///home/elasticsearch/elasticsearch-analysis-ik-7.5.2.zip
在plugin中有一类叫做Analysis Plugin,该类plugin可以帮助es扩展文本分析的能力。下面我们来详细了解一下如何实现自己的analysis plugin和创建新的analyzer、tokenizer等等组件,以及如何在es中使用这些我们自己创建的插件。
Elasticsearch的分词器插件本质上使用的是Lucene的分词器插件,所以我们需要从两个部分来介绍Elasticsearch的分词器插件
- Elasticsearch如何调用Lucene的分词器插件
- Lucene如何自定义一个分词器插件
Elasticsearch调用分词器插件
如果我们需要写一个能够让Elasticsearch进行调用的插件,首先我们要实现一个继承自 org.elasticsearch.plugins.Plugin 的类,并且该类需要实现 org.elasticsearch.plugins.AnalysisPlugin 接口参考(一)。你可以重写 AnalysisPlugin 接口的 getAnalyzers 方法,该方法最终会返回一个 org.apache.lucene.analysis.Analyzer 的对象,该对象就是一个实现了自定义分词操作的Lucene类型对象;你也可以重写 AnalysisPlugin 接口的 getTokenizers 方法,该方法最终会返回一个 org.apache.lucene.analysis.Tokenizer 的对象,该对象实现了你自定义的分词逻辑。关于这些自定义Lucene分词器的创建会在下一节进行详细介绍。AnalysisPlugin接口中还包含了一些其它的方法,更多信息可以参考该类的源代码。
下面我们看一个实际的例子,首先我们创建AnalysisQianmiPlugin类,它继承Plugin类且实现了AnalysisPlugin接口,它还重写了AnalysisPlugin接口的getAnalyzers方法,具体如下
1 | public class AnalysisQianmiPlugin extends Plugin implements AnalysisPlugin { |
上面的类中我们定义了两个ES的Analyzer,它们的名字分别为qm_standard和sub,我们选择qm_standard分析器的provider即QianmiStandardAnalyzerProvider参考(二)来做进一步的了解,QianmiStandardAnalyzerProvider的实现如下
1 | public class QianmiStandardAnalyzerProvider extends AbstractIndexAnalyzerProvider<Analyzer> { |
QianmiStandardAnalyzerProvider继承自Elasticsearch的AbstractIndexAnalyzerProvider类,并且重写了 public Analyzer get() 方法,该方法返回一个 org.apache.lucene.analysis.Analyzer 对象,具体Analyzer类的实现会在后一节中做进一步介绍。在AnalyzerProvider类的构造方法中我们还传入了Elasticsearch的一些属性,包括了
| 属性 | 含义 |
|---|---|
| IndexSettings | Elasticsearch中索引的信息 |
| Environment | Elasticsearch的环境属性 |
| AnalyzerName | 当前分析器的名称 |
| Settings | 当前分析器的属性 |
上面传入的这些属性我们可以在Lucene的分词过程中根据需要进行使用。
在创建了上面的类并且实现了相应的分词逻辑之后,我们可以对代码进行打包得到一个jar。之后我们把该jar包和一个ES插件的描述文件放在同一个文件夹中,然后把这个文件夹打包为一个zip文件,得到的这个zip文件就是一个ES的plugin了。
Elasticsearch的描述文件固定为 plugin-descriptor.properties,它一般包含了如下的内容
# 插件的描述信息
description=${project.description}
# 插件的版本号
version=${project.version}
# 插件的名称
name=${elasticsearch.plugin.name}
# 插件的全限定路径,就是之前继承自Plugin的那个类的全限定路径
classname=${elasticsearch.plugin.classname}
# 使用的Java版本信息
java.version=${elasticsearch.plugin.java.version}
# 插件对应的Elasticsearch的版本
elasticsearch.version=${elasticsearch.version}
随后我们可以使用如下命令将该pulgin安装到Elasticsearch中
./bin/elasticsearch-plugin install file:///Users/derobukal/elasticsearch-analysis-ansj/target/releases/elasticsearch-analysis-qianmi-7.5.2-release.zip
Lucene自定义分词器插件
在上面Elasticsearch调用分词插件的介绍中我们已经知道了Elasticsearch最终会需要一个 org.apache.lucene.analysis.Analyzer 的对象来实现真正的分词操作,下面我们就来了解一下我们如何定义一个这样Lucene的类。如下就是一个例子,QianmiStandardAnalyzer继承自Analyzer并且重写了其createComponents方法
1 | public class QianmiStandardAnalyzer extends Analyzer { |
方法createComponents返回了一个TokenStream,TokenStream会协助生成token。在上面的方法中我们使用到了一个名为QianmiStandardTokenizer的类,这个tokenizer实现了最终的分词逻辑。我们也可以看到我们在Elasticsearch中所提到的character_filter、tokenizer和token_filter其实都是Lucene中的概念,在这里我们只用到了tokenizer,其实在createComponents也是可以定义一些filter的,因为这里没有用到就不介绍了。
QianmiStandardTokenizer继承自org.apache.lucene.analysis.Tokenizer类,该类需要重写Tokenizer类的public boolean incrementToken()和public void reset()方法。除此之外,Tokenizer还需要用到一些attribute来保存分词的信息。
attribute属性
attribute属性用于保存我们分词的一些结果信息,例如分词本身、分词的类型、分词的位置、分词的长度,等等。如下我们定义了三个属性
1 | // 分词的属性 |
当我们得到分词之后,只需要把这些信息保存到attribute中,后续的流程可以从这些attribute取出相应的数据。
incrementToken()方法
每一次该方法执行就会得到一个分词结果,如果该方法返回true则表示还存在分词可以继续获取,返回false则表示分词已经获取完毕,我们只需要在该方法中把得到的分词信息保存我们上面所说的attribute中,Lucene会从属性中获取到这些分词的结果信息。
需要注意的是,在执行这个方法时需要先执行clearAttributes()方法来清除attribute属性的中信息,目的是为了防止上一次的分词信息对这一次的分词结果产生影响。下面我们看一个该方法的例子
1 | public boolean incrementToken() throws IOException { |
reset()方法
该方法在每段文本分词前都会调用,目的是恢复一些环境属性,防止多个文本的分词互相影响。注意在重写该方法时需要调用super.reset()以协助恢复一些Lucene本身的环境属性。假设我们需要在每次文本分析前恢复文本读取的offset变量
1 | public void reset() throws IOException { |
在Lucene分词插件这一小节我们知道了如何定义Analyzer、Tokenizer以及如何在Tokenizer中实现分词逻辑。
参考
(一)
除AnalysisPlugin之外,如果你想实现一些其它类型的插件,那么只需要创建一个继承自Plugin的类并且实现指定的插件接口即可,Elasticsearch所有的Plugin Interface在类Plugin的文档中都有详细的介绍。总结起来在Elasticsearch中创建插件的简单流程就是创建一个继承自Plugin类并且实现了指定类型插件(例如AnalysisPlugin)的接口的类。
(二)
这里的QianmiStandardAnalyzerProvider::new是一个lambda表达式,其转化过程如下:
- 这里需要一个实现了接口AnalysisModule.AnalysisProvider的类的对象;
- AnalysisModule.AnalysisProvider接口有一个get方法为虚拟方法,实现该接口的类需要实现该方法;
- 我们并不需要真的去实现一个类并且让该类实现这个get方法,而是可以使用匿名内部类的方式实现;
- (如果不使用匿名内部类)
- 实现一个类,让该类实现AnalysisModule.AnalysisProvider接口;
- 该类也需要实现get方法,get方法的逻辑还是一样的;
- 之后在这里创建一个该类的对象即可;
- 如果使用匿名内部类,则只需要实现get方法即可:
1
2
3
4
5
6new AnalysisModule.AnalysisProvider<AnalyzerProvider<? extends Analyzer>>() {
public AnalyzerProvider<? extends Analyzer> get(IndexSettings indexSettings, Environment environment, String name, Settings settings) throws IOException {
return new QianmiSubAnalyzerProvider(indexSettings, environment, name, settings);
}
} - 由于该接口只需要实现一个get方法,所以可以使用lambda表达式对如上的代码优化如下:
1
2
3(indexSettings, env, name, settings) -> {
return new QianmiSubAnalyzerProvider(indexSettings, env, name, settings);
} - 由于该方法的方法体只有一行,所以可以把上面的表达式进一步的优化为如下的lambda表达式:
1
(indexSettings, env, name, settings) -> new QianmiSubAnalyzerProvider(indexSettings, env, name, settings)
- 由于get方法的参数和后面创建对象的参数一致,所以可以使用lambda表达式进行进一步的优化:
1
QianmiSubAnalyzerProvider::new
(三)
如何在Lucene中调用Analyzer进行分词呢?在Lucene的官网中有如下文档

具体的使用方式如下
1 | String content = "如何在Lucene中调用Analyzer进行分词呢?在Lucene的官网中有如下文档"; |
(四)
如何在Elasticseach中使用指定的分词器呢?在插件安装完毕之后,我们重启Elasticsearch节点。之后在创建索引时我们可以指定字段的类型
PUT http://localhost:9200/test
{
"settings": {
"analysis": {
"analyzer": {
"default": {
"type": "qm_standard"
},
"prefix": {
"type": "sub",
"section": "0:3;0:5"
},
"postfix": {
"type": "sub",
"section": "-6:-1;-4:-1"
}
}
}
},
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "qm_standard"
}
}
}
}
如上我们可以使用默认的分析器如qm_standard,也可以根据已存在的分析器定义一些新的分析器,例如prefix分析器就来自于sub分析器。其中自定义分析器的配置信息会传到上面提到的AnalyzerProvider类的Settings变量中,我们可以使用这些配置信息来定义一些新的分词逻辑。
下面是一个使用指定分析器在Elasticsearch中进行分词测试的例子
POST http://localhost:9200/test/_analyze
{
"analyzer": "postfix",
"text": "TCC20040112442814525679"
}
{
"tokens": [
{
"token": "525679",
"start_offset": 17,
"end_offset": 22,
"type": "word",
"position": 0
},
{
"token": "5679",
"start_offset": 19,
"end_offset": 22,
"type": "word",
"position": 1
}
]
}
相关文档
Elasticsearch的文本分析
ELasticsearch的插件体系
使用Java实现Elasticsearch自定义插件的参考文档
Elasticsearch源码中关于插件部分的示例
自定义Lucene的分词器Analyzer
Package org.apache.lucene.analysis
Apache LuceneTM 8.3.0 Documentation
https://github.com/RitterHou/elasticsearch-analysis